Datenqualität: Vom Informationsfluss zum Informationsgehalt
warum sich sauberes Daten(qualitäts)management auszahlt
von Sandra Wartner, MSc
Entscheidungen zu treffen ist nicht immer einfach – besonders dann nicht, wenn diese für die grundlegende Ausrichtung des Unternehmens relevant sind und damit Einfluss auf eine weitreichende Unternehmensstruktur nehmen können. Umso wichtiger ist es, im Entscheidungsfindungsprozess möglichst alle Einflussfaktoren zu kennen, Fakten zu quantifizieren und diese (anstatt Annahmen zu treffen) direkt miteinzubeziehen, um potenzielle Risiken zu minimieren und kontinuierlich Verbesserungen in der Unternehmensstrategie zu erzielen. Ein möglicher Quick-Win für Unternehmen lässt sich aus den Unternehmensdaten ableiten: zukunftsorientiertes Datenqualitätsmanagement – einem Prozess, dem leider häufig viel zu wenig Aufmerksamkeit geschenkt wird. Warum das Vorhandensein großer Datenströme meist nicht ausreicht, welche ausschlaggebende Rolle der Zustand der gespeicherten Daten in der Datenanalyse und im Decision Making spielt, wie man gute Datenqualität erkennt und warum das auch für Ihr Unternehmen wichtig werden kann, erklären wir Ihnen hier.
Inhalt
Was kosten schlechte Daten?
Datenbasis und Datenqualität – Was steckt dahinter?
Wie erkennt man schlechte Datenqualität und wie können diese Datenmängel überhaupt erst entstehen?
Daten als Treibstoff für Machine Learning Modelle
Erfolgsfaktor Datenqualität
Quellen
Autorin
Was kosten schlechte Daten?
Im Supermarkt achten wir beim Einkauf auf das Bio-Gütesiegel und Produkt-Regionalität, bei neuer Kleidung soll das Material aus erneuerbaren Rohstoffen bestehen und keinesfalls durch Kinderarbeit produziert werden, und der Stromanbieter wird nach Kriterien wie Sauberkeit und Transparenz ausgewählt – weil wir wissen, welchen Einfluss unsere Entscheidungen mit sich ziehen können. Warum dann nicht auch in der Datenhaltung- bzw. im Datenmanagement dem Prinzip Qualität vor Quantität treu bleiben?
In Zeiten von Big Data werden im Sekundentakt Informationsfluten generiert, die häufig als Grundlage für Business-Entscheidungen dienen. Treffen wir die falschen Entscheidungen, kann das einer Studie des MIT1 zufolge sogar bis zu 25% des Umsatzes kosten. Zusätzlich zum finanziellen Verlust ist unnötig hoher Ressourceneinsatz bzw. Mehraufwand zum Beheben der dadurch entstandenen Fehler und Richtigstellen der Daten notwendig, und der Anteil zufriedener Kundinnen und Kunden sowie das Vertrauen in den Wert der Daten sinkt. Nicht nur Google hatte bislang mit drastischen Folgen von Fehlern im Datenbestand zu kämpfen, u.a. mit ihrem Produkt Google Maps2. Dabei führten Adressangaben am falschen Standort sogar soweit, dass ein Abrissunternehmen versehentlich das falsche Haus dem Erdboden gleichgemacht hat; fälschlicherweise geringere Kilometerangaben zum Navigationsziel über nicht existierende Straßen ließen Autofahrer*innen in der Wüste stranden oder Sehenswürdigkeiten schienen plötzlich an falschen Stellen auf. Auch die NASA musste am 23.9.1999 zusehen, wie beim Anflug auf den Mars die Mars Climate Orbiter und damit mehr als 120 Mio. $ verglühten – der Grund: ein Einheitenfehler3. Auch wenn die Auswirkungen schlechter Datenqualität nicht ganz so weitreichend sein können wie bei den großen Playern, betrifft das Thema Datenqualität dennoch jedes Unternehmen.
Dabei ist Datenqualität aus unternehmerischer Sicht kein IT-Problem, sondern ein Business-Problem. Dieses resultiert meist daraus, dass Business Professionals die Wichtigkeit der Datenqualität nicht bzw. zu wenig bewusst ist und sukzessive auch das Datenqualitätsmanagement schwach ausgeprägt ist oder überhaupt fehlt. Die Verknüpfung von Datenqualitätspraktiken mit Geschäftsanforderungen verhilft dabei, Ursachen für Qualitätseinbußen zu identifizieren und zu beheben, die Fehlerquote und Kosten dadurch zu senken und schlussendlich bessere Entscheidungen treffen zu können.
Abbildung 1: Von der Datenqualität zu nachhaltigen Entscheidungen und Produkten
Trotz der oben genannten Kriterien ist es nicht einfach, gute oder schlechte Datenqualität anhand von konkreteren Merkmalen zu beschreiben, da Daten in unterschiedlichsten Strukturen existieren, die sich stark in ihren Eigenschaften unterscheiden. Der gesammelte Datenbestand im Unternehmen setzt sich abhängig vom Strukturierungsgrad aus unterschiedlichen Daten zusammen:
Strukturierte Daten sind Informationen, die einem vorgegebenen Format bzw. einer definierten Struktur folgen (meist in Tabellenform aufbereitet) und gegebenenfalls sogar systematisch sortiert sind. Damit eignen sich diese besonders für Suchanfragen spezifischer Teile an Informationen wie bspw. einem bestimmten Datum, Postleitzahl oder Namen.
Unstrukturierte Daten hingegen liegen in einer nicht normalisierten, nicht identifizierbaren Datenstruktur vor und erschweren dadurch die Verarbeitung und Analyse. Darunter fallen beispielsweise Bilder, Audiodateien, Videos oder Text.
Semi-strukturierte Daten folgen einer Grundstruktur, die sowohl strukturierte als auch unstrukturierte Daten beinhaltet. Ein klassisches Beispiel dafür sind Emails, für die u.a. Absender, Empfänger und Betreff im Nachrichtenkopf angegeben werden müssen, der Inhalt der Nachricht jedoch aus beliebigem, strukturlosem Text besteht.
Datenbasis und Datenqualität – Was steckt dahinter?
Es gibt bereits viele Definitionen zum Begriff Datenqualität, dennoch lässt sich eine allgemeine Aussage darüber nur bedingt treffen, da gute Datenqualität meist domänen-spezifisch definiert ist. Ein großes Datenset alleine (Quantität) ist noch kein Indiz dafür, dass die Daten wertvoll sind. Entscheidend für den tatsächlichen Nutzen der Daten im Unternehmen ist vor allem, ob diese die Realität korrekt widerspiegeln (Qualität) und ob die Daten für den vorgesehenen Anwendungsfall geeignet sind.
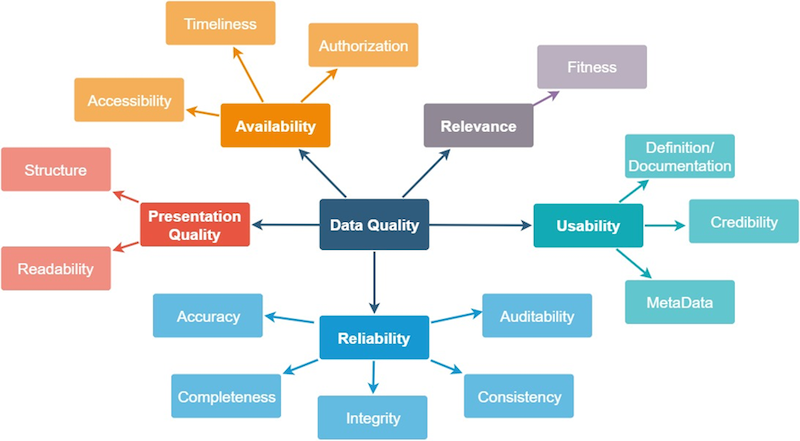
Es gibt verschiedene allgemeine Ansätze und Leitfäden zur Bewertung der Qualität von Daten. Oftmals wird gute Datenqualität sehr eng als die inhaltliche Korrektheit verstanden, wodurch andere wichtige Aspekte wie Vertrauenswürdigkeit, Verfügbarkeit oder Verwendbarkeit ignoriert werden. Cai und Zhu (2015)4 beispielsweise definieren die in Abbildung 2 dargestellten Datenqualitätskriterien Availability, Relevance, Usability, Reliability und Presentation Quality. Im folgenden werden einige relevante Punkte für die Durchführung von datengetriebenen Projekten anhand dieser Kriterien diskutiert.
Abbildung 2: Datenqualitätskriterien nach Cai and Zhu (2015)
Relevanz: Bei Datenanalyseprojekten ist es zu Beginn besonders wichtig, sich bewusst zu überlegen, ob die Daten, die dem Vorhaben zugrunde liegen sollen, für den gewünschten Anwendungsfall geeignet sind. Bei KI-Projekten ist es daher immer wichtig, folgende Frage mit “Ja” beantworten zu können: Sind die Informationen, die zum Beantworten der Fragestellung benötigt werden, überhaupt zur Gänze in den Daten vorhanden? Wenn selbst Domänenexpert*innen diese Informationen in den Daten nicht ausmachen können, wie soll dann eine KI die Zusammenhänge lernen? Machine Learning Algorithmen arbeiten schließlich auch nur mit den ihnen zur Verfügung gestellten Daten und können keine Information generieren oder verwerten, die nicht in diesen enthalten ist.
Verwendbarkeit: Oftmals werden Metadaten gebraucht, um Daten richtig interpretieren und damit überhaupt nutzen zu können. Beispiele hierfür sind etwa die Kodierung, Herkunft oder auch Zeitstempel. Die Herkunft kann beispielsweise auch Auskunft über die Glaubwürdigkeit der Daten geben. Je nach Inhalt der Daten ist auch eine gute Dokumentation wichtig – werden beispielsweise Codes verwendet, ist zur Interpretation vielleicht wichtig, wofür diese stehen, oder es werden zusätzliche Informationen benötigt, um Datumswerte, Zeitstempel oder ähnliches richtig lesen zu können.
Zuverlässigkeit: Der wahrscheinlich wichtigste Aspekt bei der Bewertung von Daten und ihrer Qualität ist, wie richtig und verlässlich diese sind. Dabei ist entscheidend, ob die Daten nachvollziehbar sind, ob sie vollständig sind und ob es Widersprüche darin gibt – schlicht, ob die enthaltenen Informationen stimmen. Wenn man schon das Gefühl hat, dass man den eigenen Daten und ihrer Richtigkeit nicht vertraut, wird man auch Analyseergebnissen oder darauf trainierten KI-Modellen nicht vertrauen. In diesem Zusammenhang ist oft auch Genauigkeit ein entscheidender Faktor: Für eine Fragestellung sind grob gerundete Werte vielleicht ausreichend, während in einem anderen Fall die Genauigkeit auf mehrere Nachkommastellen essenziell ist.
Präsentationsqualität: Daten müssen logischerweise nicht nur von Computern, sondern vor allem auch von Menschen “verarbeitet” werden können. Sie müssen also in vielen Fällen gut strukturiert sein bzw. aufbereitet werden können, damit sie auch für uns Menschen lesbar und verständlich sind.
Verfügbarkeit: Spätestens dann, wenn man bestimmte Datenmengen aktiv verwenden und z.B. in ein (KI-)System einbinden möchte, muss auch geklärt werden, wer wann auf diese Daten zugreifen darf und wie dieser Zugriff (technisch) ermöglicht wird. Gerade für Echtzeit-Systeme ist dabei logischerweise auch die Aktualität entscheidend. Denn will man Daten in Echtzeit verarbeiten (z.B. zur Überwachung von Produktionsanlagen), dann muss der Zugriff darauf schnell und zuverlässig sein.
Wie erkennt man schlechte Datenqualität und wie können diese Datenmängel überhaupt erst entstehen?
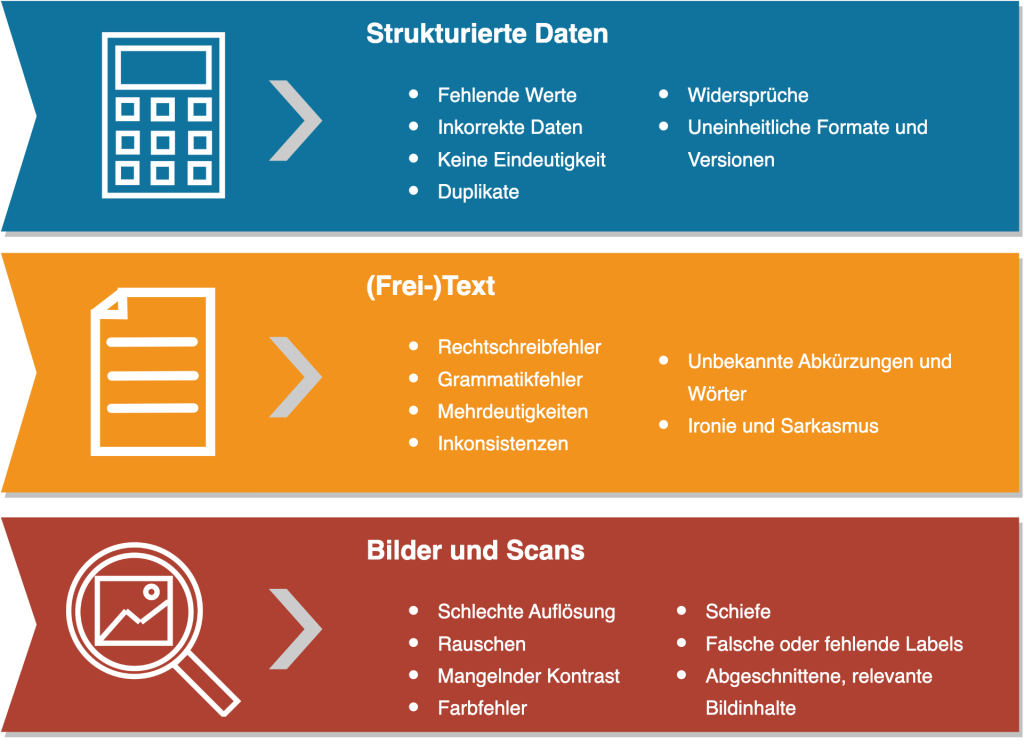
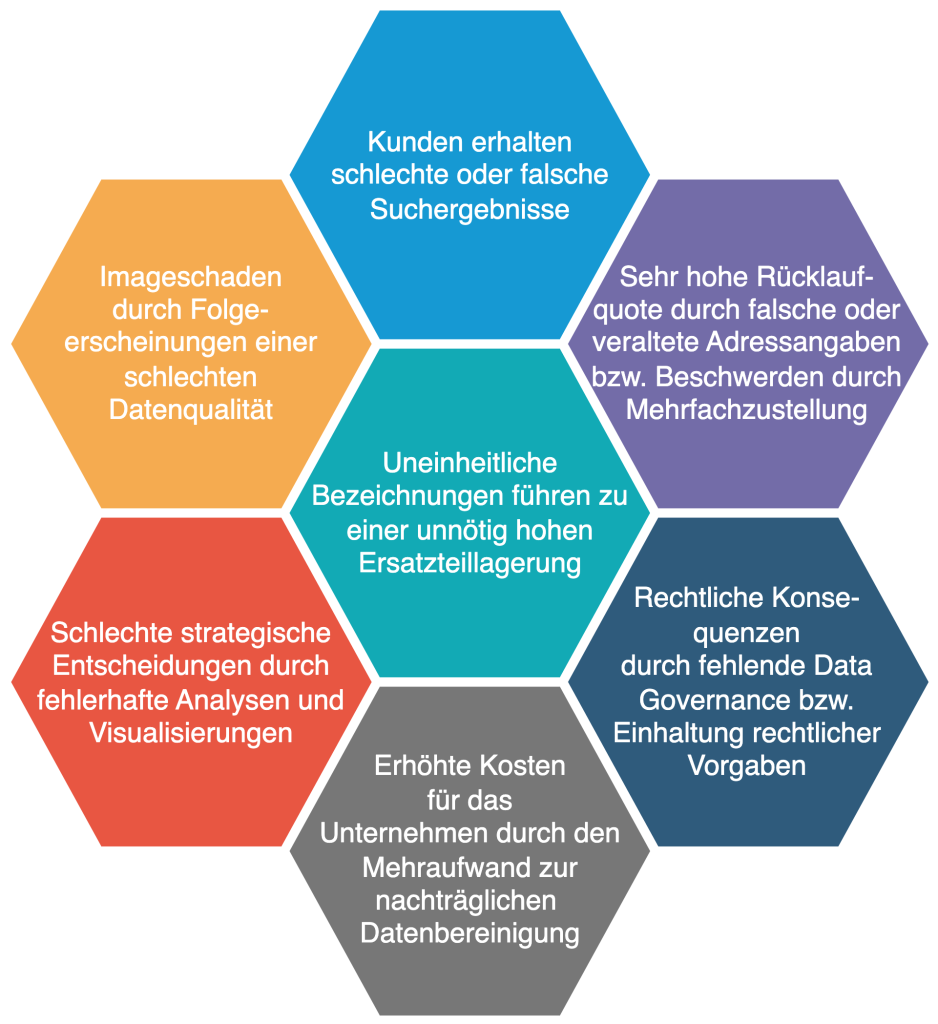
Schlechte Datenqualität ist meist nicht so unscheinbar, wie man glaubt. Bei genauerem Hinsehen äußern sich je nach Strukturierungsgrad der Daten schnell die unterschiedlichsten Mängel. Jetzt mal Hand aufs Herz – sind auch Ihnen bereits einige Fälle aus Abbildung 3 bekannt? Falls nicht, nutzen Sie doch die Gelegenheit und machen Sie sich auf die Suche nach diesen Konflikterzeugern, denn Sie werden mit sehr hoher Wahrscheinlichkeit einige davon auffinden. Diese Daten können in der praktischen Anwendung viele Gestalten annehmen und sich in unterschiedlichen Problematiken wie u.a. Imageschäden oder rechtlichen Folgen manifestieren (Abbildung 4 zeigt nur ein paar wenige der negativen Auswirkungen). Auch die Kosten schlechter Datenqualität können weitreichend sein, das haben wir in “Was kosten schlechte Daten” bereits klargestellt. Doch wie können solche Probleme überhaupt erst entstehen?
Abbildung 3: Beispiele zu schlechter Datenqualität nach Strukturierungsgrad der Daten
Abbildung 4: Negativbeispiele aus der Praxis
Die grundlegenden Ursachen liegen oftmals in den fehlenden Verantwortlichkeiten zur Datenhaltung bzw. überhaupt im fehlenden Datenqualitätsmanagement, aber auch technische Herausforderungen können Probleme verursachen. Oftmals schleichen sich diese Fehler auch über die Zeit ein. Besonders fehleranfällig sind unterschiedliche Datensammlungsprozesse und im Weiteren das Zusammenführen von Daten aus verschiedensten Systemen oder Datenbanken. Auch menschliche Eingaben produzieren Fehler (z.B. Tippfehler, Verwechslung von Eingabefeldern). Ein weiteres Problem liegt in der Datenalterung: Besonders dann, wenn Änderungen in der Datenerfassung bzw. -aufzeichnung stattfinden (z.B. fehlende Sensordaten bei Maschinenumstellung, mangelnde Genauigkeit, zu kleine/zu große Abtastrate, fehlendes Know-How, sich ändernde Anforderungen an die Datenbasis) kommt es zu Problemen. Weitere Risikofaktoren sind die (oftmals fehlende) Dokumentation und die (folglich fehlerhafte) Versionierung der Daten.
Die perfekte Datenqualität ist in der Praxis normalerweise eine utopische Vorstellung, die auch durch viele nicht oder nur schwer steuerbare Einflussfaktoren geprägt wird. Das soll allerdings niemandem die Hoffnung nehmen, denn: Meist erzielen bereits kleine Maßnahmen eine große Wirkung.
Daten als Treibstoff für Machine Learning Modelle
Nicht nur in der klassischen Datenanalyse sollte den Daten ein besonderes Augenmerk geschenkt werden, um die maximale Aussagekraft der Ergebnisse zu erhalten. Besonders im Bereich der Künstlichen Intelligenz (KI) spielt die verfügbare Datenbasis eine entscheidende Rolle und kann einem Projekt zum erfolgreichen Abschluss verhelfen oder dieses zum Scheitern verurteilen. Durch den Einsatz von KI – konkret von Machine Learning (ML)-Modellen – können sich häufig wiederholende Prozesse intelligent automatisiert werden. Beispiele sind die Suche nach ähnlichen Daten, das Ableiten von Mustern oder das Erkennen von Ausreißern bzw. Anomalien. Essentiell dabei ist überdies, ein gutes Datenverständnis zu haben (Domänen-Expertise), um potenzielle Einflussfaktoren zu identifizieren und diese kontrollieren zu können.Bekannte Prinzipien wie “decisions are no better than the data on which they’re based” und der klassische GIGO-Gedanke (garbage in, garbage out) unterstreichen dabei klar, wie wesentlich die notwendige Datenbasis für den Lernprozess der ML-Modelle ist. Denn nur wenn die Datenbasis repräsentativ ist und die Realität so wahrheitsgetreu als möglich abbildet, kann auch das Modell lernen zu generalisieren und sukzessive die richtigen Entscheidungen zu treffen.
Erfolgsfaktor Datenqualität
Für datenbasierte Arbeiten sollte Datenqualität definitiv an erster Stelle stehen. Weiters sollte das Bewusstsein zur Relevanz guter Datenqualität geschaffen bzw. nachgeschärft werden, um unternehmensweit positive Auswirkungen erzielen zu können, Kosten zu senken und freigewordene Ressourcen effizienter für die wirklich wichtigen Tätigkeiten einsetzen zu können. Unser Fazit: Ein gutes Datenqualitätsmanagement spart mehr als es kostet, ermöglicht den Einsatz neuer Methoden und Technologien und verhilft zu nachhaltigen Entscheidungen.