Wissensgewinn durch Datensammlung und -auswertung im Zeitverlauf
von Dominik Falkner, MSc
Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet. Data Science ermöglicht es, aus Daten nützliches Wissen zu extrahieren. Dabei sind Daten so vielfältig wie Menschen. Sie sind nicht nur unterschiedlich in ihrer Form – wie nominal, ordinal oder kardinal – um aus ihnen Wissen abzuleiten, ist bei vielen Daten eine Erfassung über eine zeitliche Dauer essentiell. Daher werden Daten oft über einen Zeitverlauf gemessen – es entstehen sogenannten Zeitreihen. Eine Zeitreihe besteht aus einer Reihe von Datenpunkten, welche nach einem Zeitstempel (z.B. der Form 1.1.2021 11:00:01) sortiert sind. Zeitreihen findet man in den verschiedensten Branchen, egal ob in der Industrie (von Fertigungsprozessen abgeleitet), Medizin (EKGs) oder am Finanzmarkt (Börsenkurse). Oft sind Zeitreihen ein zentraler Punkt für Entscheidungen, bringen aber einige Herausforderungen für die Datenanalyse mit sich. Der folgende Artikel zeigt anhand von Beispielen, wie die explorative Datenanalyse mit Zeitreihen gestaltet werden kann.
Inhalt
Data Science: Schöne neue Welt
Zeitreihen-Exploration: Was direkt ins Auge fällt
Expert-in-the-Loop: Zusammenarbeit ist das Wichtigste
Fazit
Autor
Data Science: Schöne neue Welt
Data Science ist zwar bereits eine jahrzehntelang etablierte Wissenschaft, für viele Unternehmen ist sie jedoch noch neu, da sie erst jetzt einen Nutzen für sich daraus erkennen. Der Hype der letzten Jahre um dieses Thema ließ viele Industrie- und Wirtschaftsunternehmen Data Science ohne etablierte Ansätze einführen. Dies führte dazu, dass viele Daten ohne Annotierungen vorliegen und das Wissen darüber auf ausgewählte Expertinnen und Experten gestreut ist. Die größte Herausforderung dabei ist, zu wissen, wie Daten zustande kommen, wie Systeme reagieren und wie die Daten zu interpretieren sind. Dieses Wissen ist sowohl bei Data Scientists als auch bei Fachexpertinnen und -experten des Anwendungsgebietes verteilt und muss durch intensive Zusammenarbeit erst generiert werden. Der Erfolg von Data Science-Projekten hängt somit stark von der Kooperation der verschiedenen Wissensträger ab.
Zeitreihen-Exploration: Was direkt ins Auge fällt
Der Mensch hat eine sehr gute und schnelle visuelle Wahrnehmung, dadurch kann er Zusammenhänge anhand von Bildern schneller verstehen als durch das Lesen der rohen Zahlen und Texte. Visualisierungen sind hervorragend dafür geeignet, dass sich Expertinnen und Experten einen umfassenden Überblick über komplexe Daten verschaffen. Diagramme dienen als kritisches Werkzeug zur Erklärung der Dateneigenschaften. Der Fallstrick dabei ist jedoch, dass gut gestaltete Visualisierungen zwar enorm hilfreich sind, naive Versuche aber oft in die Irre führen können und sich schnell als ineffektiv erweisen. Bevor aber mit der Umsetzung von Visualisierungen begonnen werden kann, ist ein anderer Aspekt bei Zeitreihen ausschlaggebend: die sog. Samplingrate. Die Samplingrate gibt an, wie oft das Analogsignal über den Messzeitraum abgetastet wird und bestimmt daher wie genau der Vorgang beobachtet wird. Sie wird bereits beim Erheben von Werten festgelegt. Meist wird sie von den Fachexpertinnen und -experten vorgegeben, da die Samplingrate ohne Vorwissen nur schwer bestimmt werden kann. Die Samplingrate beeinflusst auch die Aufzeichnungsdauer und die Datengröße: eine sehr hohe Samplingrate kann zu einem immensen Speicherverbrauch führen, was sowohl die Verarbeitung als auch die Datenhaltung schwieriger gestaltet. Wenn Analysen bereits brauchbare Ergebnisse zeigen, kann es sinnvoll sein, die Samplingrate herunter zu setzen und damit Speicherplatz zu sparen und Berechnungen zu beschleunigen. Für die Weiterverarbeitung von Algorithmen wird weiters oft vorausgesetzt, dass die Abtastrate zwischen Zeitreihen gleich ist.
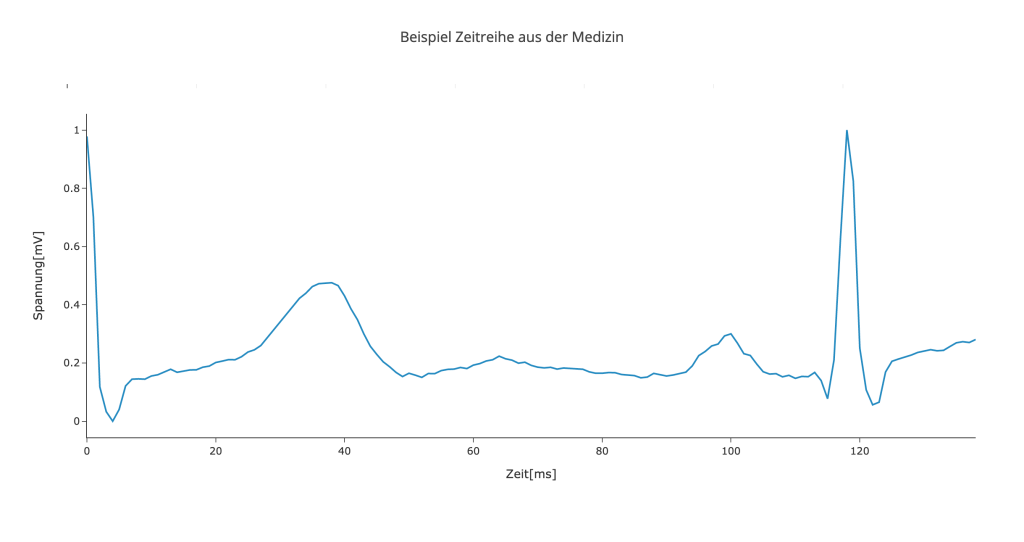
Abbildung 1: Beispiel Zeitreihe aus dem Medizinischen Bereich. Zeigt eine Ableitung des Elektrokardiogrammes.
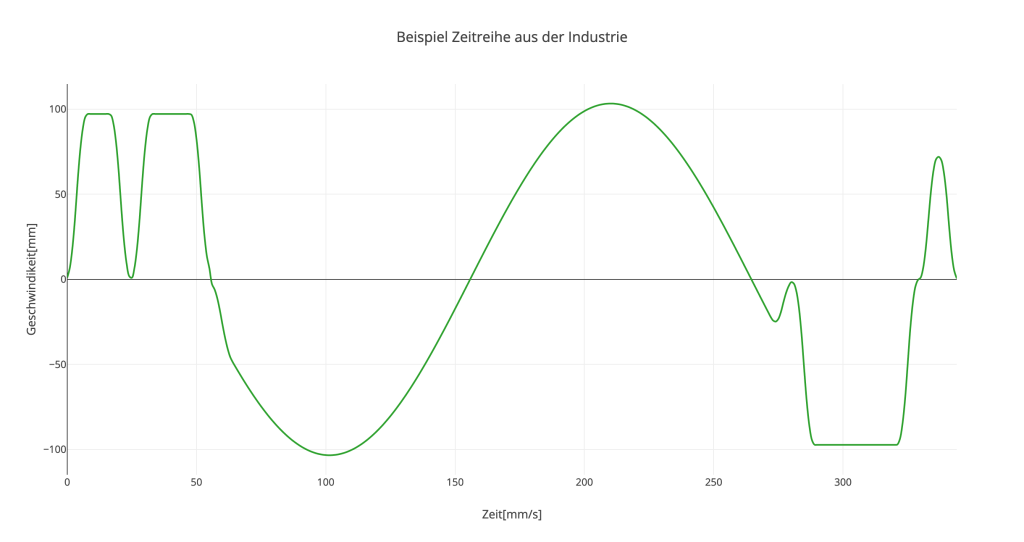
Abbildung 2: Beispiel Zeitreihe aus der Industrie. Zeigt die Geschwindigkeit mit der sich eine Maschine bewegt.
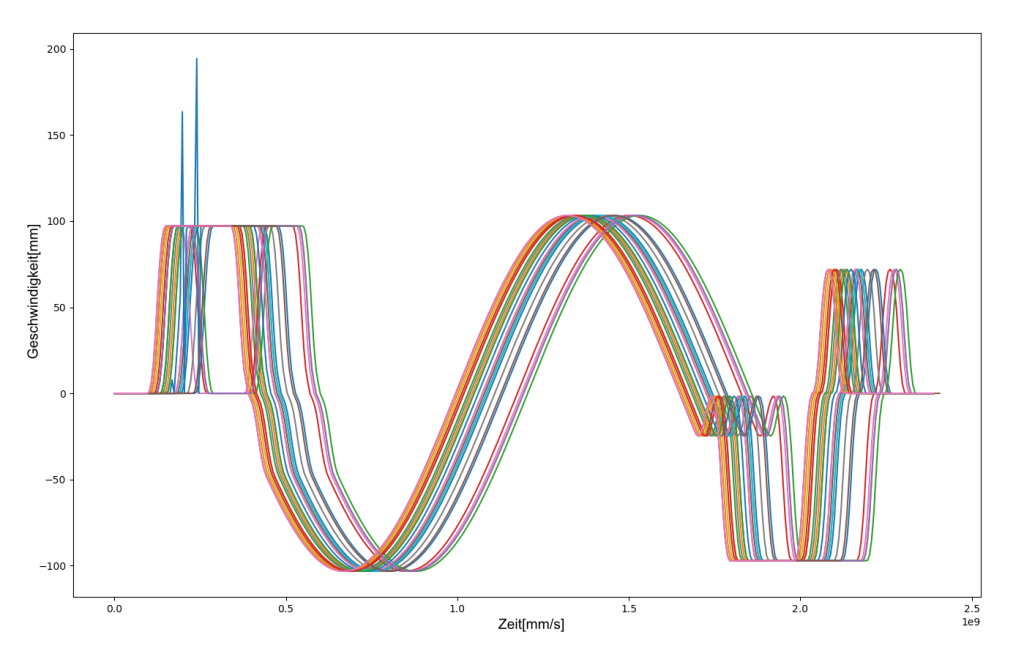
Abbildung 3: Überlagerndes Liniendiagramm mehrerer Zeitreihen. Dient oft als Ausgangspunkt für erste Analysen und bietet einen guten Überblick.
Wie in Abbildung 1 und 2 zu sehen, gibt es unterschiedliche Arten von Zeitreihen. Die erste Grafik zeigt eine Ableitung eines Elektrokardiogramms (EKG), welches als Entscheidungsgrundlage für Defibrillatoren dient, ob dieser einen elektrischen Impuls senden darf oder nicht. Die zweite Grafik zeigt physikalische Werte, die aus einem Fertigungsprozess extrahiert wurden. Beide Vorgänge treten wiederholt auf und können deshalb verglichen werden. Oft werden diese Vorgänge auch kontinuierlich aufgezeichnet, was zu einer langen kombinierten Zeitreihe führt. In diesem Fall muss diese zuerst in einzelne Sequenzen zerlegt werden, die dann übereinander gelegt werden. An diesem Punkt kann mithilfe der explorativen Datenanalyse ohne großem Aufwand nach Mustern und Gemeinsamkeiten in den Sequenzen gesucht werden. Meist ist es notwendig, die Zeitreihen zu visualisieren. Die simpelste Form dafür ist das überlagernde Liniendiagramm, ein Beispiel dafür zeigt Abbildung 3. Diese Darstellung erlaubt es, schnell mehrere Zeitreihen zu vergleichen und bewahrt gleichzeitig den Überblick. Je nachdem, wie viele Zeitreihen gleichzeitig angezeigt werden, kann es sinnvoll sein, interessante Datenpunkte (z.B.: Die neueste Zeitreihe oder jene mit besonderen Eigenschaften) hervorzuheben.
Eine weitere Möglichkeit ist es, die Daten selbst zu filtern. Oft existieren Umgebungsparameter, welche den Vorgang beeinflussen wie zum Beispiel die Außentemperatur. Das macht es leichter, Muster zu identifizieren. Diese Visualisierungen werden von Data Scientists aber auch von Domänen-Expertinnen und Experten genutzt. Das Ziel ist dabei eine enge Zusammenarbeit zwischen Domänen-Expertinnen und Experten und Data Scientists, damit möglichst viele Erkenntnisse aus den Daten gezogen werden können.
Expert-in-the-Loop: Zusammenarbeit ist das Wichtigste
Algorithmen allein können keine Erkenntnisse aus Daten gewinnen – noch schwieriger ist es, wenn die Daten nicht annotiert vorliegen. Auch Fachexpertinnen und -experten können Probleme oft nicht alleine lösen. Das fehlende Bindeglied dazwischen, um beide Welten miteinander zu verknüpfen, ist das Konzept des “Expert-in-the-Loop”. Hierbei werden die vom Algorithmus gefundenen Informationen und das Wissen und die Erfahrung, die Expertinnen und Experten über viele Jahre gesammelt haben, kombiniert. Die Hauptidee ist, die Ergebnisse eines Algorithmus zu verbessern bzw. zu kontrollieren. Die Ergebnisse können dann verwendet werden um die Analysen anzureichern. Die neuen Informationen helfen Expertinnen und Experten beim Suchen von Mustern und können Zusammenhänge aufzeigen, welche vorher nur schwer zu erkennen waren. Zusätzlich können Expertinnen und Experten Feedback geben was der Algorithmus gut erkennt und was nicht. Aufgrund dessen kann das maschinelle Lernen adaptiert werden.
Eine weitere Möglichkeit, Fachpersonal beim Explorieren von Daten zu unterstützen, ist die Bedienbarkeit der Oberfläche möglichst interaktiv zu gestalten. Ist die Visualisierung der Daten nur statisch und können die Fachexpertinnen und -experten damit nicht interagieren, sind die Möglichkeiten der visuellen Erfassung sehr begrenzt. Ist es hingegen möglich, Einfluss auf die Darstellungsoptionen zu nehmen, erweitern sich die Perspektiven und damit die Chance Zusammenhänge zu finden. Die Integration des Domänenwissens funktioniert am besten, wenn die Daten in einer Weise visualisiert werden können, die für Expertinnen und Experten interpretierbar ist. Einerseits ist es notwendig, Visualisierungen zu erstellen, welche die verschiedenen Eigenschaften der Daten ausdrücken, und andererseits muss es eine Schnittstelle sein, die einfach zu verstehen ist und es ermöglicht, Domänenwissen hinzuzufügen.
Fazit
Zeitreihenanalyse ist eine hervorragende Möglichkeit um aus Daten im Zeitverlauf Erkenntnisse zu gewinnen. Besonders die Visualisierung unterstützt Menschen dabei, Zusammenhänge und Muster zu erkennen. Dies ist besonders wichtig, damit Fachexpertinnen und -experten die Daten mit ihrem Domänenwissen anreichern und so in Zusammenarbeit mit dem Data Science Prozess einen erheblichen Mehrwert aus den Daten generieren.
Eine weitere Möglichkeit, Zeitreihen miteinander zu vergleichen, ist das Zeitreihen-Clustering. Dies stellt eine eigene Methode dar, um Daten automatisiert nach Mustern zu durchsuchen. Lesen Sie mehr dazu in einem unserer nächsten Fachbeiträge.