Transformer-Modelle erobern Natural Language Processing
Wie Sie vortrainierte Modelle wie Google T5 optimal nutzen
von Sandra Wartner, MSc
Künstliche Intelligenz (KI) ist mittlerweile zum festen Bestandteil unseres Alltags geworden. Täglich sind wir mit zahlreichen Systemen in Kontakt, welche auf KI aufbauen – auch wenn wir uns dessen nicht immer bewusst sind. Auffällig wird es jedoch dann, wenn Maschinen in unserer Sprache mit uns kommunizieren, wie das bei Sprachassistenten der Fall ist. Beim KI-getriebenen Verständnis natürlicher Sprache konnten in den vergangenen Jahren erhebliche Fortschritte erreicht werden, unter anderem durch sogenannte Transformer-Modelle – darunter auch die von Google entwickelte T5-Architektur, welche in diesem Artikel vorgestellt wird.
Inhalt
Was ist Google T5?
Parlez-vouz français? Oui!
Wie verwende ich T5 für meinen Use-Case?
Fazit
Referenzen
Autorin
Das Feld der natürlichen Sprachverarbeitung (Natural Language Processing, kurz NLP) beschäftigt sich mit dem Verständnis natürlicher menschlicher Sprache. Einen Einstieg in das Thema bietet der Fachartikel OK Google: Was ist Natural Language Processing?.
Da zum maschinellen Aufbau von Verständnis für natürliche Sprache überaus große Mengen an Textdaten von mehreren Gigabyte nötig sind (bspw. der gesamte Text aus Wikipedia), ist das Training von NLP-Systemen von Grund auf mit erheblichen Kosten (bis zu sechsstelligen Euro-Beträgen oder mehr) und Zeitaufwand verbunden[1], bis eine akzeptable Qualität der Ergebnisse erreicht werden kann. Deswegen stellen zahlreiche Forscher*innen sowie auch Großunternehmen wie Google oder Facebook vortrainierte Sprachmodelle öffentlich zur Verfügung. Da diese sogenannten Basismodelle bereits ein grundlegendes Verständnis für Sprache erlernt haben, können andere Forscher*innen auf diesen Modellen aufbauen und sie für ein konkretes Vorhaben anpassen, erweitern und wiederum mit der NLP-Community teilen.
Dieses Konzept wird als Transfer-Learning bezeichnet. Hierbei werden Modelle mit riesigen Datenmengen darauf trainiert, ein allgemeines Verständnis für grundlegende Konzepte (in diesem Fall natürlicher Sprache) zu erlangen, und anschließend mit spezielleren Daten darauf trainiert, eine konkrete Aufgabe zu erledigen. Dies erlaubt nicht nur die Wiederverwendung von Modellen, sondern verringert auch die Größe der für eine konkrete Aufgabe benötigten Datenbasis.
Wenn nur wenige Daten zur Verfügung stehen, kann man auf Zero-Shot-Learning zurückgreifen. Hierbei wird ein Modell dazu gebracht, eine Aufgabe zu erfüllen, auf welche es nicht explizit trainiert wurde. Nach diesem Prinzip arbeiten auch One-Shot und Few-Shot Modelle. Somit können Modelle mit keinen oder nur wenigen Daten auf eine bestimmte Aufgabe getrimmt werden. Leider ersparen diese Ansätze das Sammeln von Trainingsdaten in sehr vielen Fällen nicht völlig: erstens dienen diese Zero-Shot-Modelle oftmals nur als Prototypen bzw. Baseline-Modelle, da diese häufig nicht ausreichend gut generalisieren können (d.h. sinkende Qualität der Ergebnisse bei neuen, ungesehenen Daten) und sehr anfällig für Fehler in den (Trainings-)Daten sind. Zweitens sind zusätzlich Evaluierungsdaten nötig, um die Qualität der Zero-Shot-Modelle überhaupt erst quantifizieren zu können und eine Einschätzung für den durch ihren Einsatz erzielten Mehrwert getroffen werden kann.
Einen der größten Durchbrüche der letzten Jahre im NLP-Bereich stellt die Entwicklung sogenannter Transformer-Modelle dar. Hierbei handelt es sich um eine besondere Architektur von neuronalen Netzen, welche sogenannte Attention-Mechanismen verwendet und die zuvor vorherrschenden rekurrenten neuronalen Netze (RNN) durch tiefe Feed-Forward-Netze ersetzt. Diese neuartige, 2017 entwickelte Architektur konnte die Schwächen der Vorgängermodelle weitgehend ausmerzen. Sie ermöglicht u.a. ein (besseres) Verständnis über den Kontext bestimmter Wörter und erleichtert den performanten Umgang mit größeren Datenmengen. Das wohl bekannteste Beispiel einer Gruppe von Transformer-Modellen stellt BERT[2] (Bidirectional Encoder Representations from Transformers) dar. Die grundlegenden BERT-Modelle können um maßgeschneiderte Erweiterungen ergänzt werden, welche auf die gewollte Aufgabe (z.B. Klassifizierung von Sätzen auf negative, neutrale oder positive Stimmung) trainiert werden. Auf der BERT-Architektur basierende Systeme konnten seit der Publikation in 2018 in zahlreichen Aufgaben rekordbrechende Ergebnisse erzielen und sind mittlerweile fester Bestandteil der Google-Suche.
Was ist Google T5?
Die von Google entwickelte T5-Architektur[3] (Text-To-Text-Transfer-Transformer) funktioniert sehr ähnlich wie BERT, weist aber einige Unterschiede auf. Das namensgebende Text-To-Text-Prinzip bedeutet, dass bei T5-Modellen Ein- und Ausgabe aus reinen Textdaten bestehen. Dies erlaubt das Trainieren der T5-Modelle auf beliebige Aufgaben, ohne die Modellstruktur selbst auf diese Aufgabe anpassen zu müssen. So kann jedes Problem, welches als Text-Eingabe zu Text-Ausgabe formulierbar ist, durch T5 bearbeitet werden. Dazu zählen beispielsweise Klassifizierung von Texten, Zusammenfassung eines langen Textes, oder die Beantwortung von Fragen über den Inhalt eines Textes.
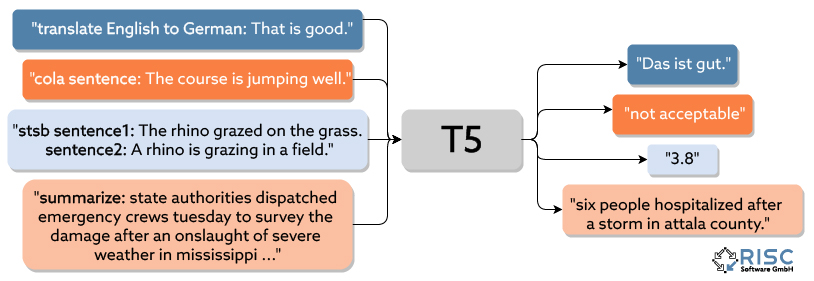
Eine weitere Besonderheit der T5-Architektur ist die Möglichkeit, mit einem einzigen Modell mehrere unterschiedliche Aufgaben lösen zu können, wie in Abbildung 1 dargestellt. So wurden die vortrainierten T5-Modelle bereits auf 17 verschiedenen Aufgaben trainiert. Darunter stellt vor allem die Aufgabe, Fragen zu einem gegebenen Text zu beantworten, eine besondere Stärke von T5 dar. Wird dem Modell der gesamte Wikipedia-Artikel zur Geschichte Frankreichs zur Verfügung gestellt, so kann bspw. auf die Frage „Wer wurde 1643 König von Frankreich?“ erfolgreich die richtige Antwort „Ludwig XIV“ zurückgegeben werden.
T5 konnte in unterschiedlichen Bereichen bereits beeindruckende Resultate erzielen, ist allerdings wie in allen Bereichen der künstlichen Intelligenz keine Lösung für jedes Problem (siehe auch No-Free-Lunch-Theoreme). Ein gängiger Ansatz zur Bestimmung der besten Lösung eines Problems ist das Testen mehrerer Modellarchitekturen für eine Aufgabe mit anschließendem Vergleich derer Resultate.
Abbildung 1: Mehrere verschiedene Aufgabentypen (z.B. Übersetzung, Bewertung der Sinnhaftigkeit, Vergleich des Inhalts zweier Sätze, Zusammenfassen) können mit nur einem T5-Modell bearbeitet werden. Diagramm nach [3].
Parlez-vous français? Oui!
Eine Erweiterung der T5-Modelle stellen die mT5-Modelle[4] dar, welche auf riesigen Mengen von Texten in insgesamt 108 unterschiedlichen Sprachen (Stand 2022-01) trainiert wurden. Dies erlaubt es einem einzigen Modell Aufgaben in unterschiedlichen Sprachen zu lösen. Hierbei ist allerdings auch ein deutlicher Unterschied in der Qualität der Resultate in unterschiedlichen Sprachen erkennbar – je weniger eine Sprache in den Trainingsdaten vorhanden ist, umso schlechter sind die darin erreichten Ergebnisse.
Besonders nützlich ist dabei auch, dass Sprachen, für die weniger Daten zur Verfügung stehen, von den Trainingsdaten in anderen Sprachen profitieren können. Dies ist vor allem bei der Datenakquise hilfreich, da englischsprachige Texte oft in größeren Mengen verfügbar sind als Texte in anderen Sprachen. Selbst wenn Aufgaben nur in einer Sprache gelöst werden sollen, können mT5-Modelle somit dennoch hilfreich sein, falls in der Zielsprache nicht genügend Trainingsdaten vorhanden sind. Die dabei erzielten Resultate sind zumeist allerdings eher schlechter als wenn mit einer ähnlichen Menge an Gesamtdaten nur auf der Zielsprache trainiert worden wäre.
Wie verwende ich T5 für meinen Use-Case?
In einem ersten Schritt sollten einige allgemeine, wichtige Fragen über den konkreten Use-Case geklärt werden:
In welchen Sprachen ist das Problem zu lösen?
Woher stammen die für das Training nötigen Daten? Sind diese für meinen Use-Case geeignet?
Wie kann ich die Qualität des Modells überprüfen (sind Testdaten vorhanden)?
Welche Ressourcen (Rechenleistung, Zeit, finanzielle Mittel etc.) stehen für ein Training bzw. Fine-Tuning zur Verfügung?
Welche Modelle sind für meinen Use-Case anwendbar?
…
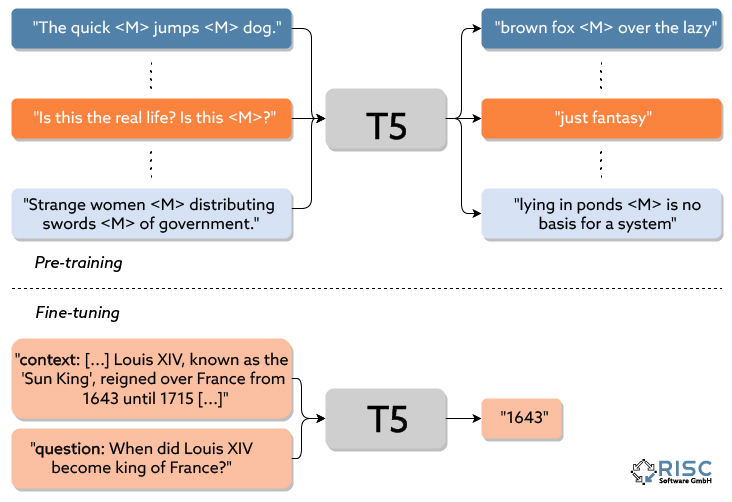
Abbildung 2: Pre-training und Fine-tuning von T5-Modellen. Diagramm nach [5].
Für den potenziellen Einsatz von T5 muss zusätzlich noch evaluiert werden, ob der Use-Case als Text-To-Text Aufgabe formuliert werden kann.
Als nächstes wird ein passendes, vortrainiertes T5-Modell gewählt. Eine der besten und bekanntesten Quellen dafür ist die Plattform Hugging Face, welche eine Vielzahl an vortrainierten State-of-the-Art Modellen und auch Datensätzen als open-source Lösungen für die Öffentlichkeit bereitstellt. Diese stehen häufig in unterschiedlichen Größen zur Verfügung, wobei eine Balance zwischen der benötigten Rechenleistung bzw. -zeit und der Qualität des Modells gefunden werden muss. Größere Modelle bieten zwar im Allgemeinen bessere Resultate, stellen allerdings auch signifikant größere Anforderungen an Ressourcen, weswegen nicht automatisch immer das größte Modell die beste Wahl ist.
Nun geht es ans sogenannte Fine-tuning. Dabei wird das vortrainierte Modell (welches zu diesem Zeitpunkt bereits über ein grundlegendes Verständnis für Sprache verfügt) darauf trainiert, eine konkrete Aufgabe wie in Abbildung 2 dargestellt zu lösen. Hierfür sind Trainingsdaten notwendig, welche dem Modell vorzeigen, welche Eingabe zu welcher Ausgabe führen soll. Dabei ist nicht nur die Menge, sondern auch die Qualität der Daten von entscheidender Bedeutung.
Herausforderungen sind unter anderem die Wahl des konkreten Basismodells, die Beschaffung und Qualitätskontrolle der Trainingsdaten und das Aufbereiten der Daten in ein vom Modell lesbares Format. Zusätzliche Schwierigkeiten kommen beispielsweise bei längeren Textsequenzen hinzu, da Transformer-Modelle über ein Limit bezüglich Textlänge verfügen.
In der RISC Software GmbH wird der Einsatz von T5-Modellen seit längerem erforscht. So konnte ein System zur Erkennung und Zuordnung von Eigennamen in Texten (Named Entity Recognition, kurz NER) durch T5 erweitert und verbessert werden. Hierzu kommt die bereits vortrainierte Fähigkeit von T5, Fragen zu einem gegebenen Text zu beantworten, zum Einsatz. So kann das T5-Modell Fragen wie „Welche Person ist betroffen?“ oder „Welches Unternehmen ist involviert?“ beantworten und somit dem NER-System unter die Arme greifen.
Fazit
Die T5-Architektur eignet sich aufgrund ihres Designs für eine Vielzahl unterschiedlichster Aufgaben (oder Kombination dieser) und konnte bereits in zahlreichen Anwendungsgebieten beeindruckende Resultate liefern. Es bleibt weiterhin äußerst spannend, wie sich diese Technologien in der Zukunft weiterentwickeln werden und welche weiteren Erfolge erzielt werden können.
Referenzen
[1] Sharir, Or, Barak Peleg, and Yoav Shoham. “The cost of training nlp models: A concise overview.” arXiv preprint arXiv:2004.08900 (2020).
[2] Devlin, Jacob, et al. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
[3] Raffel, Colin, et al. “Exploring the limits of transfer learning with a unified text-to-text transformer.” arXiv preprint arXiv:1910.10683 (2019).
[4] Xue, Linting, et al. “mT5: A massively multilingual pre-trained text-to-text transformer.” arXiv preprint arXiv:2010.11934 (2020).
[5] Adam Roberts and Colin Raffel. “Exploring Transfer Learning with T5: the Text-To-Text Transfer Transformer.” https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html