Graph databases in practice
Graph databases enable the mapping of many real-world scenarios such as: Traffic data analysis or IT infrastructure monitoring.
mehr erfahren
The great strength of graph databases – databases that use graphs to connect and store networked information in the form of nodes and edges – is the extensive mapping of relationships between data points. This enables an intuitive mapping of many real-world scenarios, which have gained a lot of importance especially during the last years. Examples include modeling relationships between people in social networks, making purchase recommendations in e-commerce, or detecting fraudulent transactions in finance. In addition to these application areas, graph databases are also useful in the fields of industrial manufacturing, traffic data analysis or IT infrastructure monitoring for identifying causal relationships.
Table of contents

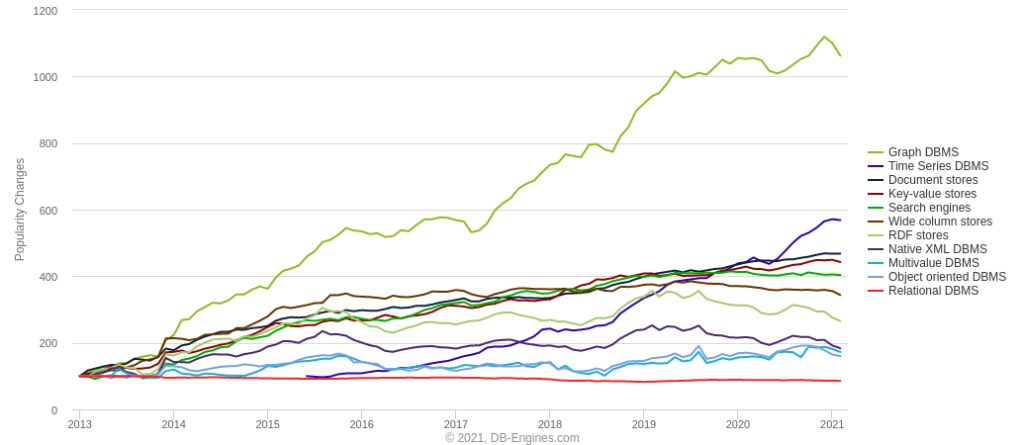
According to a survey on the popularity of database categories (https://db-engines.com/en/ranking_categories), graph databases represent the fastest growing category of database technologies over the last few years. Graph databases represent their data as sets of nodes and edges, where nodes represent data objects with attributes, while edges represent the links between the objects.
Relational databases are excellently suited for representing tabular structures, such as those commonly used in the commercial sector. By using the third normal form, the data is stored in tables clearly separated according to the objects they describe, whereby other objects with which they are related are referenced via foreign keys. The goal is, among other things, to avoid data duplication and to enable linking through flexible queries in the Structured Query Language (SQL).
These applications are also characterized by the fact that once a data model has been designed, it usually remains constant over a longer period of time. However, in problem domains where one is primarily interested in the links between data, the relational data model has weak points. Since links are mapped via foreign key relationships, queries often have to be implemented as multi-level joins, which can be very runtime-intensive, especially for large tables. In addition, many application domains contain semi-structured data whose structure changes over time. Such data is difficult to represent in the rigid data model of a relational database.
In addition, the more flexible data model of a graph database often allows it to more directly represent the reality being modeled, making both the design of the data model and the queries applied to it more intuitive. Furthermore, it is more easily adaptable in the event of changes in the application domain, since the graph can be extended without drastic changes in the data model.


Wherever relationships between data points are the focus of interest, graph databases provide a solid basis for further analysis. They allow a more direct and flexible mapping of the problem domain than relational databases.
Furthermore, they show the way from the collected data to answering the category of questions about the cause of potential or current problems:


Complex supply chains can be mapped and thus potential bottlenecks or dependencies on individual suppliers can be identified.

Correlations between sensor values and machine states are often only suspected or unknown. A collection and time-based linking of data in a graph database can reveal hidden correlations.

Graph databases can show correlations between patients‘ disease histories and the efficacy of therapies. Likewise, drug interactions can be identified.

Mapping the relationships between biological and chemical data can accelerate the development of new
pharamceuticals.

From traffic control systems to refineries and factories: control algorithms perform automated switching operations. Graph databases can help make them comprehensible to humans, detect errors and increase the efficiency of such plants.

Parameters of servers and applications can be collected automatically. Based on this, graph databases can be used to detect transitive dependencies between services as well as overloads or critical elements in IT infrastructures.
RISC Software GmbH supports you at every stage of your process to generate the greatest possible value from your data. If you wish, this also includes the selection of the right tools for your needs – such as a graph database. Companies that do not yet have end-to-end data collection or do not yet use their data for such tasks have the opportunity to gradually increase the value they derive from their data.

Senior Data Engineer