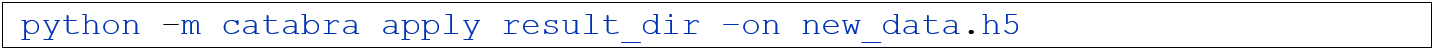Abra CaTabRa: Daten automatisiert analysieren, validieren und damit Machine Learning Modelle trainieren
von Sophie Kaltenleithner, MSc
Daten werden mittlerweile in fast allen Lebensbereichen gesammelt – seien es die gekauften Produkte beim Online-Shopping, Bewegungs- und Ernährungsinformationen in Fitness-Apps oder Maschinendaten beim Produktionsprozess. Häufiges Ziel davon: Automatisch Vorhersagen zu treffen: Welchen Zielgruppen soll mein Produkt vorgeschlagen werden? Welche Gewichtsabnahme kann ich erwarten, wenn ich täglich eine Runde laufe? Wann muss ich die Verschleißteile meiner Maschinen tauschen, um möglichst kurze Stillstandszeiten zu haben?
Damit solche Vorhersagen möglich werden, bedarf es komplexer Analysetätigkeiten und technischer Expertise. Nicht immer kann dieser Aufwand in Projekten investiert werden. CaTabRa schafft hier Abhilfe: CaTabRa ist ein Open-Source-Tool zur Automatisierung von Schritten in der Analyse von tabellarischen Daten und der Entwicklung von Vorhersagemodellen. Es eignet sich sowohl für Domänenexpert*innen ohne technischem Know-how, als auch für Data-Scientists, die effizient Informationen aus ihren Daten gewinnen möchten. Statistische Auswertungen, Training von Machine Learning Modellen, Erklärung von Modellentscheidungen, Validierung von Inputdaten. All das ist mit geringem Zutun erledigt!
Inhalt
Anwendungsbeispiel aus der Medizin: Covid-19 Detektion in Bluttests
Datenanalyse und Training
Modellerklärung – Explainable AI
Erkennung von ungültigem Input – Out-of-Distribution Detection
Fazit – Bei der Vorhersage von Covid-19 ist Vorsicht geboten
Vorteile durch den Einsatz von CaTabRa
Quellen
Autorin
Anwendungsbeispiel aus der Medizin: Covid-19 Detektion in Bluttests
Kann man COVID19 anhand von Werten eines Standard-Bluttests diagnostizieren? Mit diesem Thema beschäftigten sich Forscher*innen von JKU, KUK MedCampus III und RISC Software GmbH im Jahr 2022 [1] . Ziel war es, Covid-19 Infektionen aus routinemäßig durchgeführten Labortests nachzuweisen, um so eine große Anzahl von Patient*innen schnell und ohne Mehraufwand testen zu können. Wie ähnliche Ergebnisse allein mithilfe von CaTabRa generiert werden können, wird im Folgenden demonstriert.
CaTabRa arbeitet auf tabellarischen Daten. Zeilen sind dabei einzelne Stichproben (Samples) und Spalten deren Charakteristika (Features). In unserem Beispiel sind die Samples Patienten und die Features ihre Blutwerte. Zusätzlich muss der Zielwert definiert sein. Das kann ein numerischer Wert sein (Regression) oder – wie hier – ein kategorialer (Klassifikation): „infiziert“ und „nicht infiziert“.
Ein typischer Workflow besteht aus Anwendung der folgenden vier Schritte, die über Kommandozeilen-Befehle aufgerufen werden können:
1. Analyze
Erstellt Statistiken und trainiert Vorhersagemodelle.
2. Evaluate
Evaluiert die Modelle auf einem Testdatensatz, um ihre Qualität zu überprüfen.
3. Explain
Generiert Erklärungen für Modellentscheidungen in Form von Feature-Importance Scores.
4. Apply
Trifft Vorhersagen für neue Samples durch Anwenden der zuvor trainierten Modelle.
Abbildung 1: Der typische Workflow bei Anwendung von CaTabRa besteht aus den vier Schritten Analyze, Evaluate, Explain und Apply.
Datenanalyse und Training
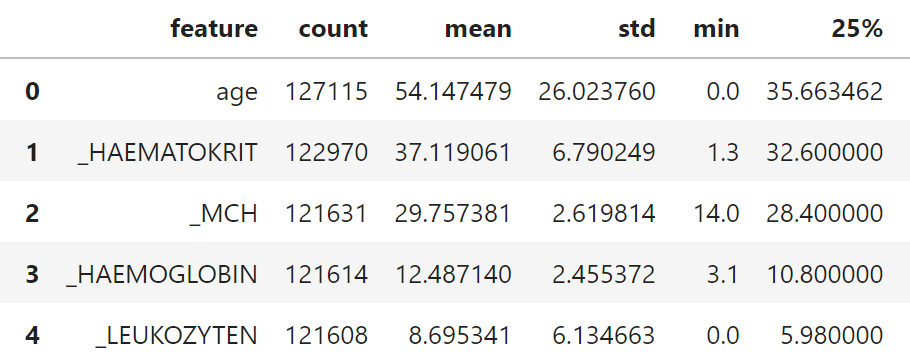
Im ersten Schritt generiert Analyze deskriptive Statistiken, die einen besseren Überblick über die Daten geben sollen. Diese werden pro Feature berechnet. Je nach Datentyp sind das etwa die Anzahl an Einträgen im Datensatz, Extremwerte, Mittelwerte, Korrelationen mit anderen Spalten etc. Die Tabellen in untenstehender Abbildung zeigt dies exemplarisch für ausgewählte Features der Covid-19 Daten.
Abbildung 2: Exemplarischer Auszug aus den Covid-19 Daten.
Im zweiten Schritt wird ein Modell trainiert, das den definierten Zielwert vorhersagt – also hier ob eine Covid-19 Infektion vorliegt. Die Qualität von Machine Learning Modellen hängt stark von den verwendeten Algorithmen und deren Konfigurationen ab. Diese können im Vorfeld nicht ohne Weiteres festgestellt werden. CaTabRa setzt deshalb auf State-of-the-Art AutoML Methoden, um schnell und ohne großen manuellen Aufwand die richtige Konfiguration zu finden. AutoML steht für „Automated Machine Learning“. Dabei werden komplizierte Optimierungsverfahren eingesetzt, um sich schrittweise der besten Lösung anzunähern – ganz ohne manuellen Aufwand.
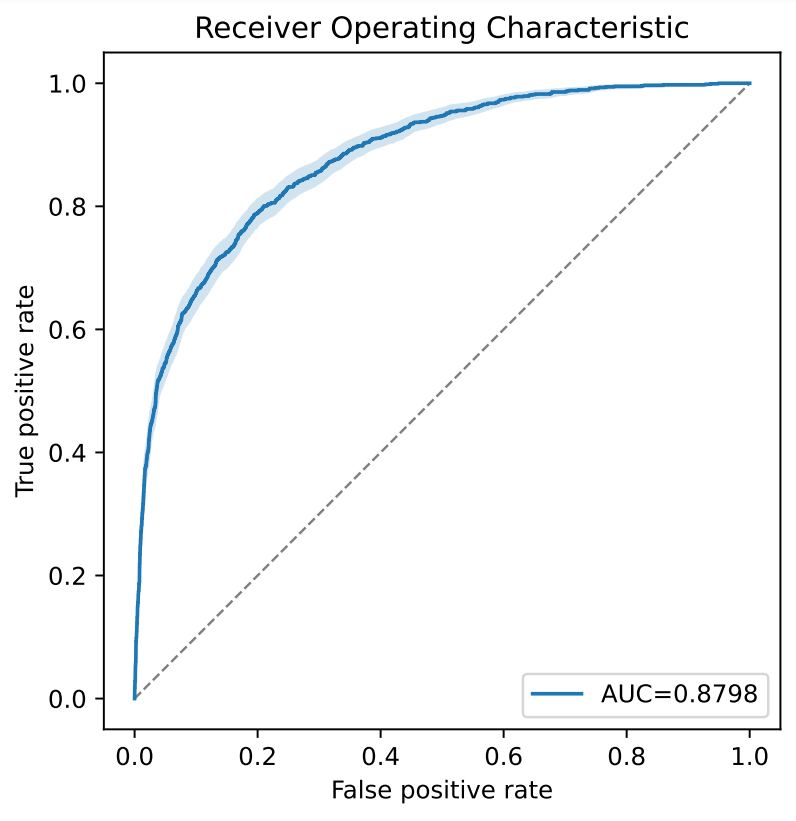
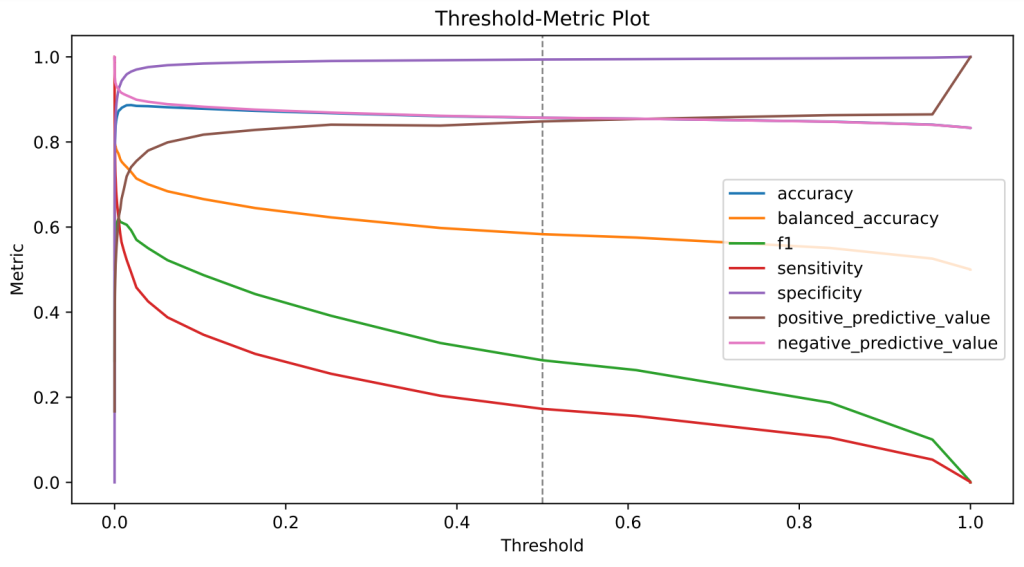
Nach Beendigung des Trainings kann über die Evaluate Funktionalität die Qualität des Modells überprüft werden. Dabei werden detaillierte Performance-Reports und entsprechende Visualisierungen erstellt. Die Auswertung wird mithilfe eines Teil des Covid-19 Datensatzes durchgeführt, der nicht zum Trainieren verwendet wurde. So kann geschätzt werden, wie gut das Modell mit neuen Daten umgehen kann. Untenstehende Abbildung zeigt Beispiele der so erhaltenen Grafiken. Diese visualisieren bestimmte Qualitäts-Metriken in Abhängigkeit der Modell-Vorhersagen. Der erhaltene ROC-AUC Wert – ein Qualitätsmaß für Klassifikationsprobleme – ist vergleichbar gut wie der in der originalen Publikation.
Abbildung 3: Beispielhafte Grafiken zur Modell-Evaluierung die von CaTabRa generiert werden. Links: ROC-Kurve; Rechts: Metrik-Werte in Abhängigkeit des Decision-Thresholds.
Modellerklärung – Explainable AI
Entscheidungen von Black-Box Machine Learning Modellen sind für Menschen nur schwer nachvollziehbar. Gerade in der Medizin ist es allerdings wichtig, den Modellen nicht blind zu vertrauen. Oft ist etwa ein ungewollter Bias in den Daten vorhanden, der die Modelle dazu veranlasst, falsche Schlussfolgerungen zu ziehen. Wären in den Trainingsdaten etwa zufälligerweise mehr Männer als Frauen an Covid-19 erkrankt gewesen, könnte es sein, dass das Geschlecht der Patient*innen zu stark in die Entscheidung miteinfließt.
CaTabRa erlaubt deshalb mithilfe der Explain Funktion die Wichtigkeit von einzelnen Features festzustellen. Standardmäßig wird dafür SHAP verwendet. Wie diese Methode im Detail funktioniert, lesen Sie im Fachbeitrag Explainable AI. Zusätzlich zu den reinen Berechnungen werden auch hier wieder automatisch aussagekräftige Visualisierungen erstellt.
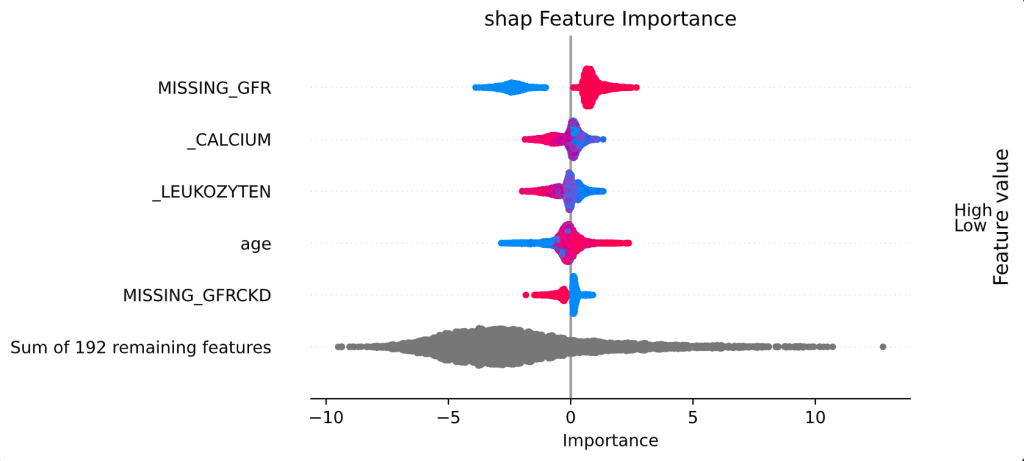
Die Abbildung unten zeigt die Feature-Importance Scores der Covid-Daten für die fünf wichtigsten Features. Ein Punkt korrespondiert dabei mit einem Sample, wobei die Farbe den Feature-Wert darstellt (blau: niedrig, rot: hoch). Die Position auf der x-Achse zeigt, wie ein Feature für ein bestimmtes Sample das Ergebnis beeinflusst. Beispielsweise deutet das Fehlen von Messungen der glomerulären Filtrationsrate („MISSING_GFR“; ein Parameter, der v.a. die Nierenfunktion misst) tendenziell auf eine Covid-Infektion hin, und auch hohes Alter scheint für den verwendeten Datensatz ein Indikator zu sein. Insgesamt achtet das Vorhersagemodell jedoch auf viele verschiedene Features, anstatt die Entscheidung an ein paar wenigen Features festzumachen.
Abbildung 4: Feature-Importance Plot für die Covid-Daten basierend auf SHAP-Werten.
Erkennung von ungültigem Input – Out-of-Distribution Detection
Modelle des maschinellen Lernens gehen im Allgemeinen davon aus, dass neu vorherzusagende Daten der Verteilung der ursprünglichen Trainingsdaten entsprechen. In der Realität kommt es allerdings häufig zu so genannten „Domain Shifts“, d.h. einer Änderung der Datenverteilung. Der Grund dafür kann vieles sein: Der Trainingsdatensatz war zu wenig repräsentativ, Messverfahren haben sich geändert, Charakteristika ändern sich über die Zeit etc. Jedenfalls sind die Modellentscheidungen in solchen Fällen nicht mehr vertrauenswürdig. CaTabRa trainiert deshalb Out-of-Distribution (OOD) Detektoren um zu überprüfen wie sehr sich ein gewisser Input von den Trainingsdaten unterscheidet. Sie werden bei Aufruf von Apply (also der Vorhersage-Funktionalität) automatisch angewendet. So wissen Anwender*innen wann sie Modell-Vorhersagen besser hinterfragen sollten.
Bei den Covid-19-Daten konnte festgestellt werden, dass Modelle, die nur auf Daten zu Beginn der Pandemie trainiert wurden, zu späteren Zeitpunkten schlechtere Vorhersagen treffen. Das könnte daran liegen, dass der Virus sich allgemein stärker in der Gesellschaft verbreitet hat, aber auch daran, dass neue Mutationen aufgetreten sind. Wenn zum Modelltraining nur Daten der ersten zehn Pandemiemonate verwendet werden und die generierten OOD-Detektoren danach auf Daten angewendet werden die auch die Monate elf und zwölf enthalten, sind bei 81 von insgesamt 95 kontinuierlichen Features geänderte Verteilungen feststellbar.
Fazit – Bei der Vorhersage von Covid-19 ist Vorsicht geboten
Was aus den Ergebnissen der originalen Publikation hervorgeht und sich auch bei Anwendung von CaTabRa wieder zeigt: Bluttests sind ein relativ guter Indikator dafür ob eine Person an Covid-19 erkrankt ist. Allerdings gilt dies nur solange wie man sich sicher sein kann, dass sich an den Eigenschaften des Virus und dessen Verbreitung nicht zuviel ändert. Wie die Meisten aber mitbekommen haben dürften, ist dies in der Realität nicht der Fall. Eine rasche Verbreitung des Virus, Lockdowns und Mutationen könnten alle zu einer geänderten Verteilung führen. Es ist deshalb ratsam die Qualtiät von Machine-Learning Modellen kontinuierlich auf aktuellen Daten zu überprüfen und gegebenenfalls neu zu trainieren.
Vorteile durch den Einsatz von CaTabRa
Es macht die Auswertung von Daten einfacher und effizienter – man kann schnell und einfach einen Einblick in die Daten gewinnen, um bspw. festzustellen, ob der Einsatz von Machine Learning Methoden Sinn macht.
Es erstellt ansprechende Visualisierungen, die man als solche direkt in Publikationen verwenden kann.
Im Gegensatz zu ähnlichen Cloud-Lösungen müssen keine sensiblen Daten hochgeladen werden, alles passiert lokal.
Es wird auf Flexibilität gesetzt: CaTabRa lässt sich einfach erweitern, sodass der Prozess durch eigene Methoden angepasst werden kann. Zusätzlich wird eine Vielzahl von Konfigurationen Out-of-the-Box angeboten.
CaTabRa ist gleichzeitig auch eine Python Bibliothek, die die einzelnen Features, sowie Methoden zur Datenaufbereitung über Programmierschnittstellen zu Verfügung stellt.
[1] T. Roland et al., ‘Domain Shifts in Machine Learning Based Covid-19 Diagnosis From Blood Tests’, J Med Syst, vol. 46, no. 5, p. 23, Mar. 2022, doi: 10.1007/s10916-022-01807-1.