Die große Stärke von Graphdatenbanken – das sind Datenbanken, die anhand von Graphen vernetzte Informationen in Form von Knoten und Kanten in Verbindung bringen und speichern – ist die umfangreiche Abbildung von Beziehungen zwischen Datenpunkten. Dies ermöglicht eine intuitive Abbildung vieler Real-World-Szenarien, die gerade während der letzten Jahre stark an Bedeutung gewonnen haben. Zusätzlich ermöglichen es Graphdatenbanken, dass sich auch die Abfragen eng an die modellierte Realität anlehnen, wie in diesem Artikel beispielhaft gezeigt wird.
Inhalt
Beispiel: IT-Systemüberwachung
Graphdatenbanken und Abfragesprachen
IT-Systemüberwachung: Gremlin-Abfragen
Datenmodellierung: Abbildung der Realität vs. Abfrageperformance
Performanz und Skalierung
Autor
Beispiel: IT-Systemüberwachung
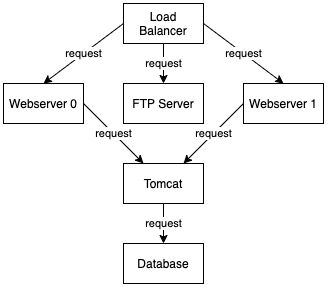
Der hier gezeigte beispielhafte Graph stellt die Abhängigkeiten zwischen den Diensten einer IT-Infrastruktur dar. Dazu werden Serverprozesse als Graphknoten modelliert, wobei die Prozesse durch Kanten verknüpft sind, die Anfragen darstellen. Die Kanten sagen damit aus, dass jeder Knoten alle seine Nachfolger entlang der Kanten benötigt, um zu funktionieren. Aus dem Beispiel ist auch direkt ersichtlich, dass es eine Graphdatenbank ermöglicht, das Datenmodell sehr nahe an der Problemdomäne zu modellieren und so das Datenmodell intuitiv verständlich zu machen.
Graphdatenbanken und Abfragesprachen
Im Bereich der Graphdatenbanken gibt es neben Angeboten unter rein kommerzieller Lizenz (z.B. TigerGraph, Amazon Neptune) auch zahlreiche mit Open-Source-Lizenzen (z.B. Neo4j, ArrangoDB, OrientDB, JanusGraph), für die teilweise auch kommerzielle Lizenzen angeboten werden. Die am meisten verbreiteten Graphdatenbank Neo4j wird beispielsweise unter einer kommerziellen sowie auch einer Open-Source-Lizenz angeboten, wobei allerdings der Einsatz der Open-Source Variante auf einen einzelnen Server beschränkt ist.
Ein weiteres Unterscheidungsmerkmal ist die verwendete Abfragesprache wobei hier vor allem Cypher und Apache Tinkerpop Gremlin zu nennen sind. Während Cypher vor allem von der Graphdatenbanklösung Neo4J eingesetzt wird, ist Gremlin aus dem Apache Tinkerpop Projekt hervorgegangen, und wird von zahlreichen Graphdatenbanken wie beispielsweise Amazon Neptune oder JanusGraph unterstützt. Da die beiden Sprachen funktional äquivalent und automatisiert ineinander überführbar sind, stellt die Kenntnis nur einer der beiden Sprachen allerdings keinen limitierenden Faktor bei der Wahl des Datenbanksystems dar.
IT-Systemüberwachung: Gremlin-Abfragen
Grundsätzlich wird zwischen lokalen und globalen Graph-Abfragen unterschieden. Während globale Abfragen den gesamten Graphen einbeziehen, sind lokale Abfragen auf einen meist kleinen Teilbereich des Graphen beschränkt. Daher sind auch globale Queries bei großen Graphen laufzeitkritisch.
Lokale Abfragen
Ein einfaches Beispiel für eine lokale Graph-Abfrage im oben abgebildeten Graph wäre: Auf welche Serverprozesse werden die Anfragen vom Load-Balancer verteilt?
Folgende Abfrage in Gremlin beantwortet diese Frage:
Gremlin-Abfragen folgen dem Modell einer Graph-Traversierung. Hierbei wird ausgehend von einer Menge an Knoten, die auch nach Typ oder gewissen Attributwerten vorgefiltert werden können, der Graph traversiert, indem adjazenten Kanten gefolgt wird.
Dieser Teil der Abfrage besagt, dass der Knoten mit dem Attributschlüssel name und dem Attributwert loadbalancer als Startpunkt für die Traversierung g dient:
Diese Abfrage ist lokal, daher hängt die Antwortzeit – wenn der Startknoten bekannt ist – nicht von der Größe des Graphen ab.
Globale Abfragen
Der Graph kann außerdem dazu eingesetzt werden, zu beurteilen, wie kritisch der Ausfall einer Komponente für das Gesamtsystem ist. Man kann nun beispielsweise eine Abfrage formulieren, die angibt wie viele andere Prozesse einen Prozess benötigen. Dazu werden alle Pfade vom Load-Balancer aus berücksichtigt. Die zugehörige Gremlin-Abfrage lautet wie folgt:
Dieser Teil der Abfrage besagt, dass die Menge aller Knoten als Startpunkt für die Traversierung g dient:
g.V()
Hier wird als Ergebnis eine Map erstellt, die als Schlüssel den Wert des Attributs name entält, was der Lesbarkeit des Ergebnisses dient.
g.V().map(union(values('name'), ...)
Hier wird für jeden Knoten über alle eingehenden Kanten (_.in()) iteriert bis der angetroffene Knoten keine eingehenden Kanten (inE()) mehr aufweist. Für jede dieser Schleifen werden die angetroffenen Knoten nach Entfernung der Duplikate gezählt (.emit().dedup().count()) und in einer Liste zusammengefasst (.fold()):
Dies ist ein Beispiel für eine globale Abfrage die über den gesamten Graphen iteriert, womit ihre Laufzeit im Gegensatz zu lokalen Queries von der Größe des Graphen abhängt.
Datenmodellierung: Abbildung der Realität vs. Abfrageperformance
Die Datenmodellierung weist für Graphdatenbanken die Vorteile auf, dass das Datenmodell eng an der Realität entworfen werden und flexibel erweitert werden kann. Andererseits hat die Struktur des Graphen auch direkten Einfluss auf die Effizienz von Abfragen, da über Verlinkungen Knoten schneller erreicht werden können. Ein guter Ansatz ist daher mit dem Entwurf des Datenmodells nahe an der Realität zu starten, und im Fall von Performanceproblemen bei Abfragen den Graphen entsprechend um zusätzliche Knoten und Kanten zu erweitern. Dadurch wird einerseits die Abbildung der Realität – und damit das Verständnis des Datenmodells – im Kern nicht beeinträchtigt, andererseits können zum Beispiel neue Abfragen effizient behandelt werden.
Performanz und Skalierbarkeit
Vergleichbar mit relationalen Datenbanksystemen bieten auch Graphdatenbanken Möglichkeiten der Indizierung von Knoten oder Kanten an. Somit ist es möglich über einen Index schnell auf alle Knoten zuzugreifen, bei denen eine Menge an Attributen als Schlüssel verwendet werden kann. Diese Ergebnismenge kann in der Folge als Startpunkt für eine Graphtraversierung verwendet werden. Zusätzlich zu den Möglichkeiten der Indizierung ist die horizontale Skalierbarkeit der Graphdatenbank ein Schlüsselkriterium, um bei einer stetig wachsenden Datenmenge nicht in Probleme mit der Abfrage-Performance zu laufen.
Als lizenzkostenfreie Lösung für eine skalierbare Graphdatenbank bietet sich zum Beispiel die Open-Source Datenbank Janusgraph an, mit der unter anderem ein Hadoop-Cluster als Speicherbackend eingesetzt werden kann. Darüber hinaus kann Apache Spark als Graph Compute Engine eingesetzt werden, um die Ausführung globaler Queries in Graphen bis in den Terrabytebereich managebar zu machen.
Die RISC Software GmbH unterstützt Sie auf jeder Stufe Ihres Prozesses, größtmöglichen Wert aus Ihren Daten zu generieren. Dies schließt nach Wunsch auch die Wahl der für Ihr Anliegen passenden Werkzeuge – wie beispielsweise eine Graphdatenbank – ein. Unternehmen, die bis jetzt noch keine durchgängige Datenerfassung haben oder ihre Daten noch nicht für solche Aufgaben nutzen, haben dabei die Möglichkeit, den Wert, den sie aus ihren Daten ziehen, schrittweise zu steigern. Aufbauend auf ihrer langjährigen Expertise im Bereich der skalierbaren NoSQL Lösungen kann somit die RISC Software GmbH auch als verlässlicher Consulting- und Umsetzungspartner für ihre maßgeschneiderte Lösung im Bereich von NoSql-Systemen und Graphdatenbanken dienen.